A pattern that I have recently seen in a project is data replication through real-time stream processing. This pattern happens when a company has all of it’s data stored on centralized databases and applications access this data, this means that two example services like “search” and “product catalog” are depending on the same data. In this situation some services cannot function by only request the data through API, they need a snapshot of the data. Do address this requirement the real-time data replication solutions come handy. With this approach we need a event driven architecture to handle incoming data and apply required transformations. All stream processing frameworks such as Kafka Streams support doing stream joins to denormalize the data and while they offer very straightforward performant solutions the join support is limited in some cases.
Streaming Changes from Database
We can start by implementing a change data capture system with a tool like
Debizium and Apache Kafka. An example architecture is the following picture: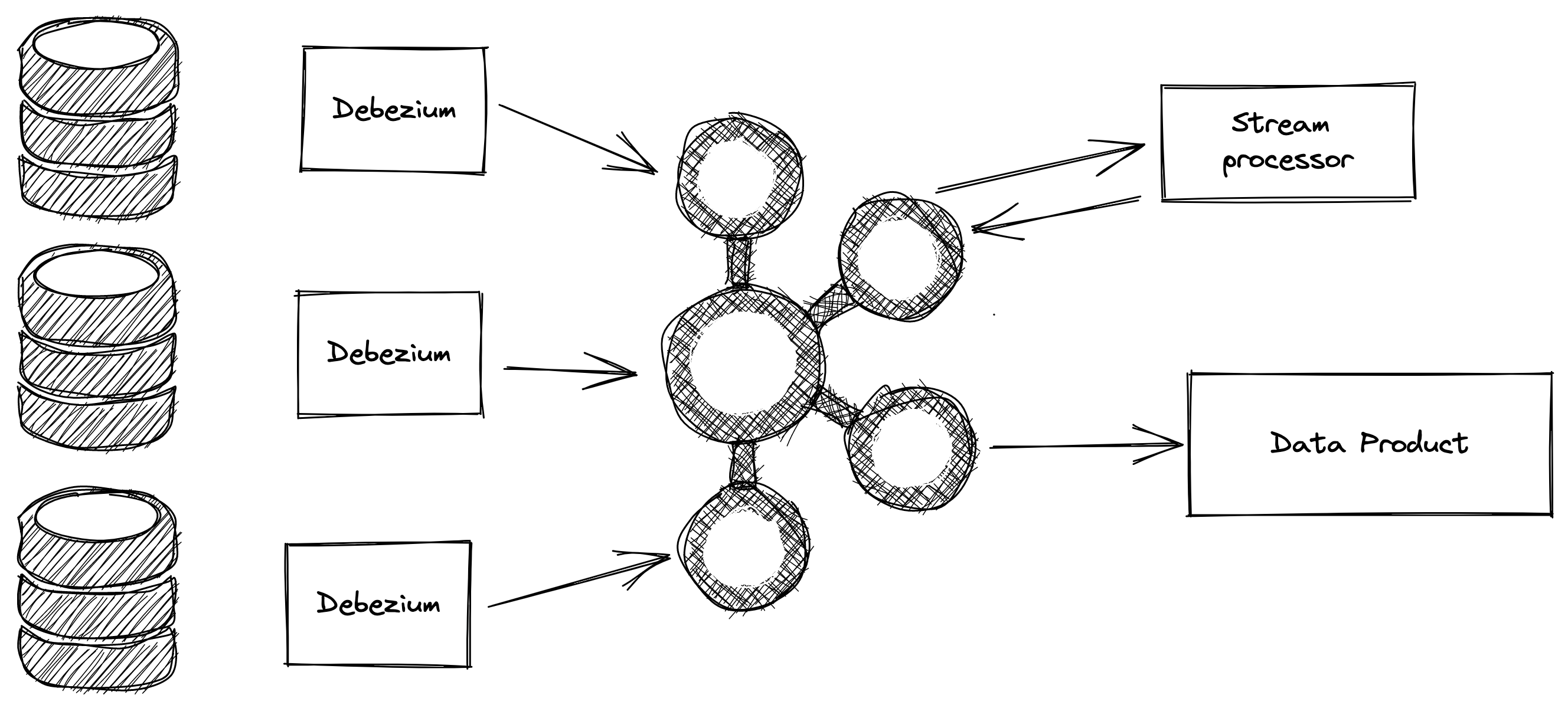
Now the downstream services can use the data product topic coming out of Kafka. Let’s focus on how to implement the stream processing component.
As discussed earlier this use case is very suitable for a tool like Kafka Streams but if we have requirements to join data like:
- Join on primary and non primary keys
- Having no time window on when the join can occur
- Support denormalizing database relations
Then you cannot utilize full power of Kafka streams. Because Kafka streams joins the data on record key then all records that are going to be joined need to be published with the same key. Now if a stream needs to be joined with multiple streams then it has to bNnne published in multiple topics with different keys. This approach will result in the following diagram
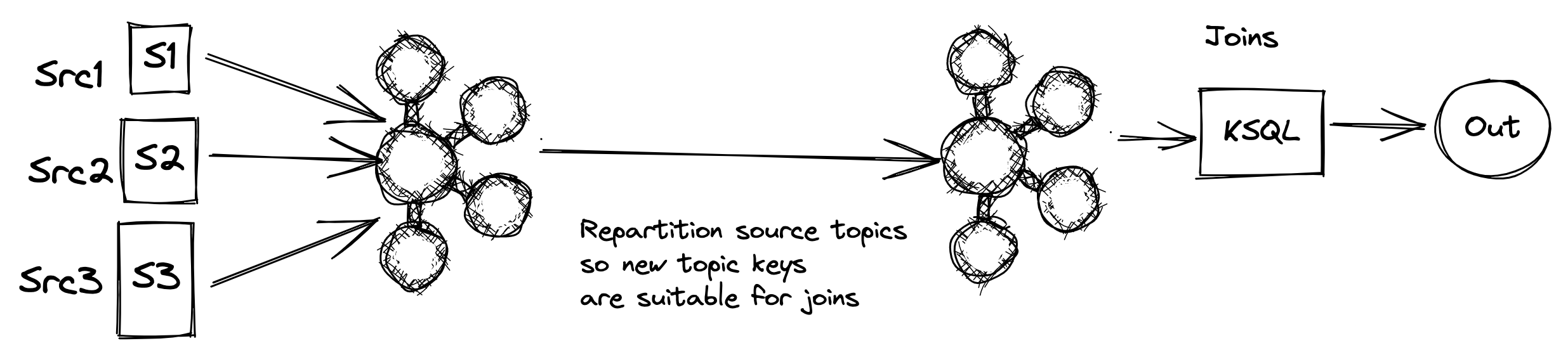
This can lead to a very expensive solution both in terms of cost and development.
Problem and Possible Solutions
Now that we know the pattern and the limit let’s try to solve it with for an example business.
My goal is to find a solution which is easy to implement not the fastest one , but a balance between easy and cost efficient and low latency solutions. It’s also possible to come up with a range of different configurations and package them as solutions so different users can choose different configurations.
Imagine you are doing this for Github, they want to extract all user data and
it’s interactions with the platform into an easy to use data structure named
UserProfile.
Let’s start by giving a very simple example data model: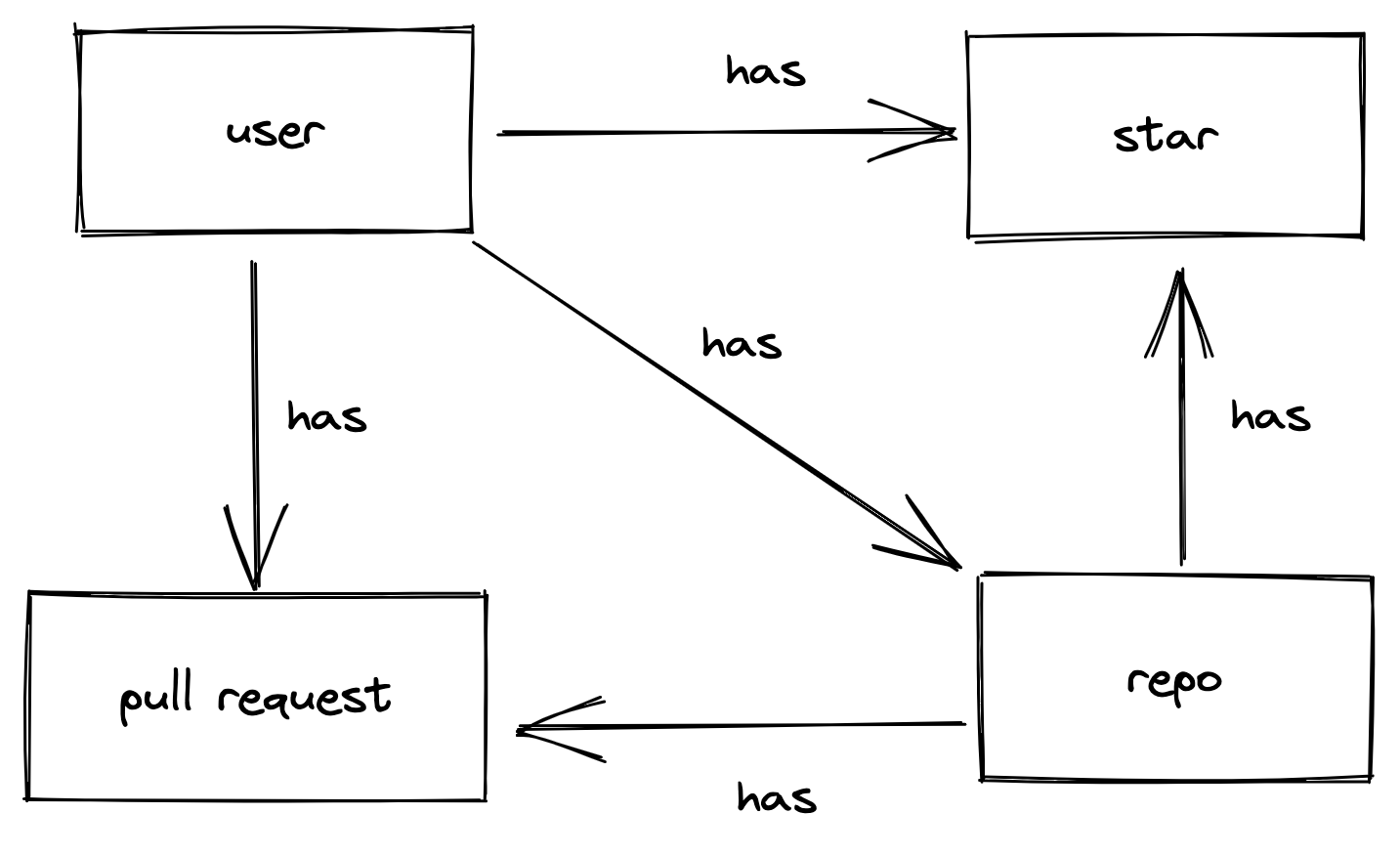
With following definitions:
User
- id
- username
- registered_at
Pk: email
Repo
- name
- owner
- description
- star_count
- fork_count
- created_at
- updated_at
Pk: (owner,name)
Pull Request
- title
- repo
- repo_owner
- index
- author
- status
- created_at
Pk: (repo,repo_owner,index)
Star
- username
- repo_name
- repo_owner
- created_at
Pk: (username, repo_name, repo_owner)
Payment Info
- id
- user_id
- verified
Pk: id
Now let’s say the UserProfile is going to have the structure:
User Profile
- username
- starred_repos (many to many rel)
- repo
- description
- pull_requests (one to many rel)
- repo
- index
- title
- created_at
- status
- payment_verified
In this case when we are consuming events form User, Pull Request and Star
table then we need to do join these streams and embed the pull request and
star information inside the UserProfile output stream.
If we start by using message keys as join keys here to join User and Pull
Request streams then the Pull Request has to be published with author field
as a key.
In case we need to create another data product for pull requests
data depends on the repo and index we need to create another stream.
Before that let’s see what query join do we need to perform on these streams to get the result.
select ...
from users
left outer join star
on star.username = username
left outer join pull_request
on pull_request.author = username
left outer join payment_info
on payment_info.id = id
Note that in this query we only want to get a single record with UserProfile
structure.
This means to embed all pull requests into record as a list, and add
payment_verified value as a single value.
Solutions
To give a solution I’m focusing on providing something that can work at huge scale, imagine we are going to create a hundred data products so system should make it very easy to onboard a new table.
Solution 1: Using RDBMS
I started with the idea of why not just moving all the computation on the database? After all the SQL language has nice features to do these transformations.
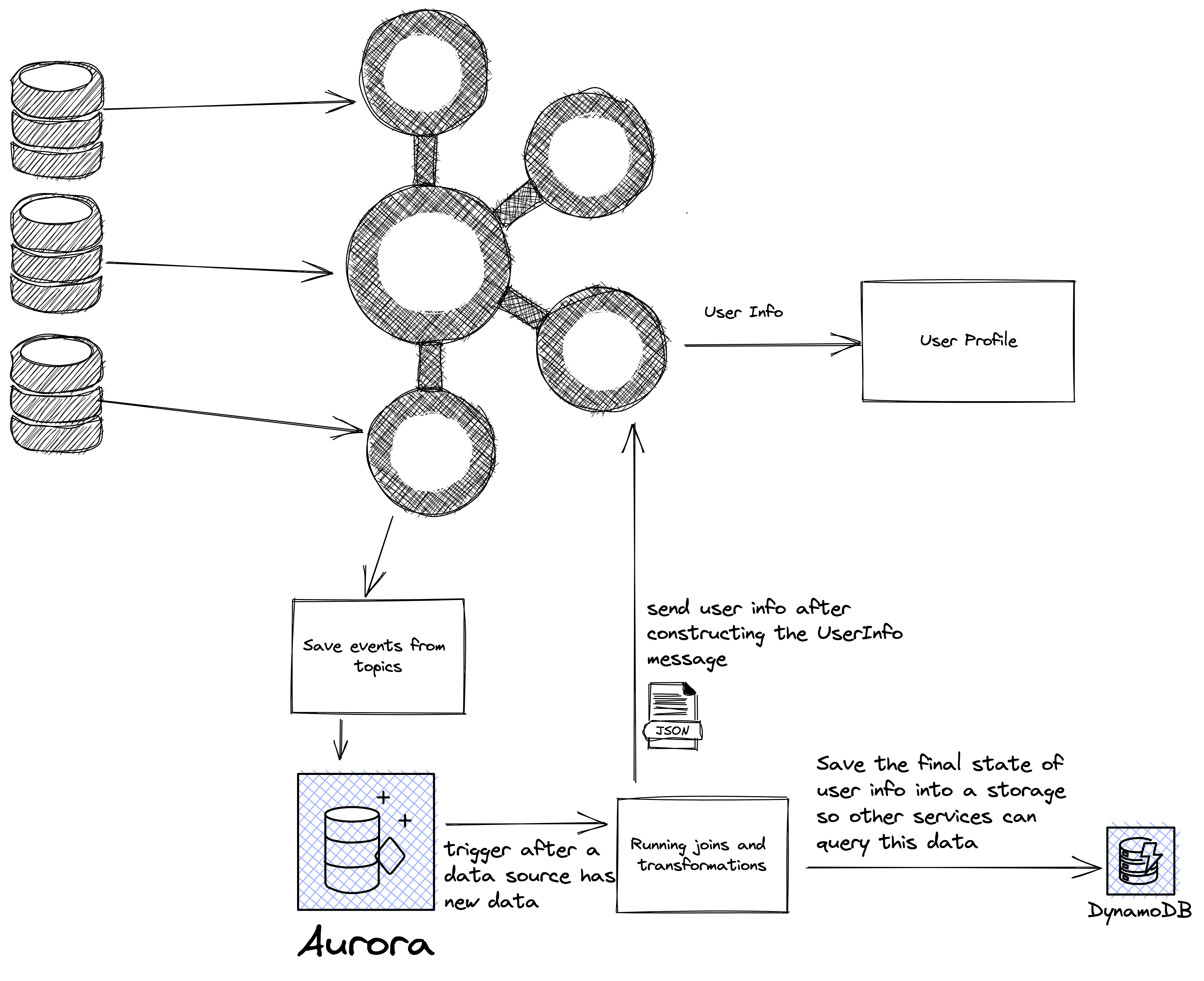
With this method we can have a generic application that reads streams and place them in database under a table with the topic name. So to onboard a new topic we have to feed this service two values:
- table name to insert data into
- table schema and mapping of event fields into table fields
After we insert the data in the database we trigger a lambda function to run the SQL query, get the data and embed the joins into a single document and produce message to Kafka.
This lambda function requires these inputs:
- a mapping from table names to SQL queries
After lambda is triggered it will lookup the mapping and run the SQL query. In our case it will get the user back with all matched pull request.
Now we need a custom logic in lambda to embed all the matched Pull Request
entities into UserInfo message.
Benefits
- Implementation is very generic
- We have all the capabilities of SQL to do the processing
- Each topic can be joined with any other topic with any valid SQL condition
Drawbacks
- The fact that we put all the computation on the database and specially join queries will result in a huge amount of costs
- The architecture is not truly real-time, we should utilize indexes on database to make sure query returns with low latency
Solution 2: Join Data In Stream Processor
To attempt to fix the previous solution drawbacks, a reasonable way can be moving the join logic to stream processor application.
In this case the stream processor has a data store named state store that is used to keep track of latests state of records consumed. To get a better understand of how the state store works, Imagine the scenario:
- A new pull request is created with information
{ title: "PR", status: "Open", ...} - Stream processor consumes the message and insert it into the state store
- The pull request is updated and it’s closed so another event is emitted with body
{ title: "PR", status: "Closed", ...} - Stream processor consumes the new event updates the previous record in the state store using the primary key of the pull request.
So at any given point the state store has latest state of an entity.
We can leverage this state store to join events as they are consumed by creating 3 tables: pull_request, user, user_info.
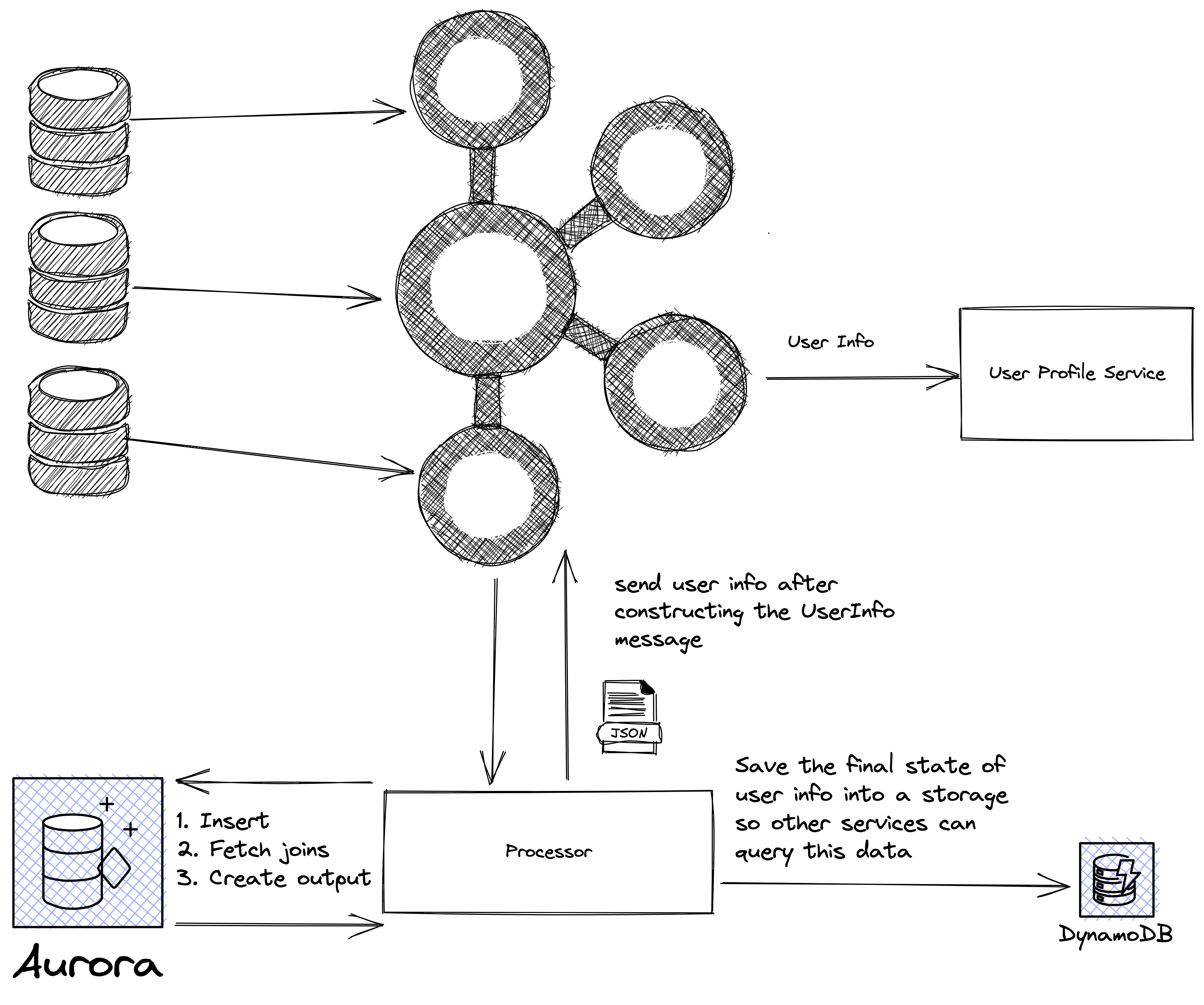
- When a pull request event is consumed and inserted into a intermediate table
- When a user event is consumed, application queries the pull request table to check if there’s any matched records with the join criteria. If there’s any it creates the user_info message and saves it into database.
- Finally application also saves the
usermessage in step 2 into database in case there’s other joins for user table.
Or in a case that the order of incoming events is not guaranteed when the user event comes in application joins it with the pull request table and creates the user_info message.
Here also based on the join type we either publish a new user_info message or not, in this case this is a left join where the left is user entity:
- If user event is consumed even if it do not match any pull request the
user_infomessage must be published. - If pull_request event is consumed
user_infomessage will only be published when pull request matches a user record, then the application updates the correspondinguser_infomessage with the new pull request and publishes the message again.
Benefits
- Ability to execute all SQL queries
- Can do complex joins
- Can index database on the fields that are queried for joins to decrease the processing time
Drawbacks
- The RDBMS database is used for a lot of read/write operations which can become slow and expensive
- The join logic is split in processing events from left and right side of the join.
Using Another Database as State Store
Following the idea of previous solution to move the join logic to application, we can make an adjustment to DB choice. The pattern is inserting a record but retrieving it only by specific fields. Usually key value store databases provide fast read and writes with this limitation.
Let’s say like the previous method processor consumes events, and saves them inside a KV store like dynamoDB. Now it’s important to specify a unique key for records so they don’t overwrite each other, primary keys are:
- User: email
- Pull request: (repo,repo_owner,index)
- Payment Info: id
When the application consumes a user event it’s required to join this field with pull requests that have the same username. This is not possible since our hash key is the PK, which is email in this case.
Now we use some auxiliary tables to make this possible.
We create a table called join_user_pr with key being the join condition value(username) and value be the primary key
of the user entity with that username, And similarly a table called join_pr_user for when joining an incoming PR event
with User.
Application can use this table as a lookup table to do joins.
An example when user event is coming in:
- Save user in
Userstable and insert record{user.username: user.email}intojoin_pr_user - Query the
join_user_prwith the username to get back primary keys of PRs which has this username. - Query the
pull_reqesttable with primary key of PR and construct theuser_infomessage and publish
When pull_request event comes in:
- Save pull_request event in
pull_requesttable and insert record{pull_request.pk: pull_request.username}intojoin_user_pr. - Query the
join_pr_usertable with pull_request username to get back user email for that PR. - Query user table with email and construct the
user_infomessage and publish
Since DynamoDB(and other KV stores) provide a fast way to read and write the process time is not going to grow in large volume of data. But we are creating duplicate data to be able to execute these queries, this can also be solved with Secondary Indexes in DynamoDB. Secondary Indexes can be fine for small number of joins but if we want to join the User with 20 different tables the cost of User table with 20 SI will be high and more than having the auxiliary tables.
Benefits
- Can support large volume of data
- Application can support multiple joins on a single record with low process time.(DynamoDB can provide 10ms read times)
Drawbacks
- Data is duplicated
- Coordination of what tables and fields to query makes the application complex, the given example has 6 steps for a single join
Leveraging the DynamoDB Global Secondary Indexes
The previous solution was really close to achieve a very good result but still the 1 lookup and 1 query per join statement can cause long process time in some cases. Now we’ll try to exploit another feature of DynamoDB, Global Secondary Indexes, to solve this problem.
Before that let’s state what we exactly need from state store:
- Being able to get all records of a topic with given join condition, for example all pull_requests with a particular username
We can use a single table for all the records to make this join possible and easier. Imagine we have a table with a composite primary key with following definition:
- Partition Key: TABLE#{table_name}
- Sort Key: entity PK
For example we insert all user records in the table with Partition Key of TABLE#users and Sort key of user.email,
The same happens for pull_request as well(we can concatenate multiple columns for the Sort Key).
Now how can we join a user with all of it’s pull_requests? Using a Global Secondary Index.
Let’s say we create a column called GSI_1(Global Secondary Index column names can be meaningless and be reused in DynamoDB),
We are going to use this column in both user and pull_request entities.
For users we insert the username value in the GSI_1 and for pull requests we insert the username in GSI_1.
When a user event comes in the application will:
- Insert it in the
usertable and fills the GSI values according to joins specified. - Query the
pull_requesttable with theGSI_1=={user.username}condition, This will return all the PRs for that username - Create the
user_infomessage and publish
When a pull_request event comes in the application will do the same things again the GSI_1 will be used and PR will be matched
with the correct user record.
Now the problem will be managing the GSI fields we create. We need to create GSI fields for every single join that an entity has.
In our example if we want to join the user record with payment info we have to create a new GSI_2 field for the user and save the user.id in that field.
But for the payment_info record we can insert the user.id in the GSI_1 field because the only join Payment Info has is with the User.
This allows us to reuse the GSI field for multiple purpose so we don’t hit the 20 GSI limit unless we have a table with 20 different joins.
Also we now can get back all pull requests for a user with a single query, this will enable us to perform multiple joins without loosing performance.
To manage the GSI fields and what they are used for in each record we need another storage to save this information. We can have a small PostgreSQL instance that knows for example in User records the GSI_1 field is used to join with Pull Request entity.