Introduction #
After reading ByteByteGo course motivated me to write a rate limiter. So I decided to do it in 500lines theme.
We will focus on how to create the interfaces and components, to allow extensibility in the predicted ways.
You can find the complete source code here.
What is a Rate Limiter? #
Well, there are a lot of great explanations on what is a rate limiter, but I’ll give a minimal introduction to it for this post.
A rate limiter is software that limits how many times someone can repeat an action in your software. Take Twitter as an example; they need to specify how often someone can send a tweet per minute; otherwise, one person can create 1 million tweets in a second and fill up all their server resources.
High Level Design #
First off, what should our rate limiter do? The rate limiter should be a function that takes in a request, decides if the request can go through or not based on the current statistics.
We are going to implement the following features:
- Rule-based rate limiting: let the user define rules
- with a simpler version (without nested rules) of envoy rate limit config.
- Support both local memory and Redis as storage backend
- Support the following rate-limit algorithms:
- Token bucket
- Fixed window
- Sliding window log
- Sliding window counter
- Distributed deployment model:
- deploying multiple instances with consistent and eventual consistency models.
What are the components of our system?
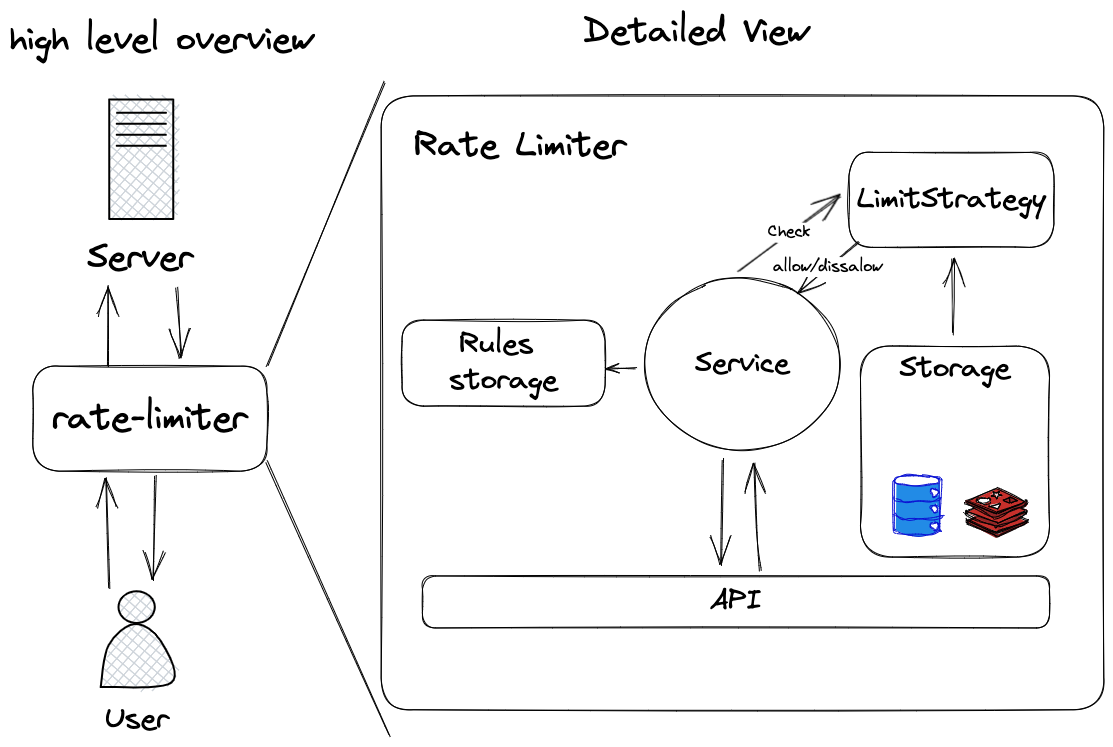
Breaking down the components:
Rules storage: it is responsible for loading rules and providing them to the rate limiter.
Separating this component allows the service independent of how the rules should be loaded into the service. We want to start the application with a set of rules saved on disk, but it’s helpful to be able to add/remove rules from an API endpoint while the application is running.
Although we will not implement that part in this guide, separating this is good for easier testing and future extensibility.
Storage : This component is responsible for holding data used by rate-limiting algorithms.
Creating an interface for storage is helpful because
we can ignore the underlying storage implementation in rate limit algorithms.
Allowing us to use multiple storage backends such as Redis or local memory
without touching the rate limit algorithm code.
We can implement operations exists, get_value, set, incr for the above algorithms.
Note that we assume that our data store for this software is a key/value store. We are not creating a general store that every application can use. This data store helps with writing a more straightforward interface and implementation for storage. For example, we don’t require to support where/filtering clause.
This video gives a nice explanation of why sometimes we must do this.
Limit Strategy: This component implements the rate limit algorithms without knowing the underlying storage or API implementation.
It should take in storage and a request and provide a result whether it’s limited.
The request details are essential to decide whether to limit, but we only need the request data, IP, and path. So it’s better only to take in these values and not depend on a particular request type. Then in the future, we can write adapters to convert a gRPC request to this function’s input format.
Service: takes care of orchestrating all the components. Upon startup, it loads all the rules into memory and creates a list of limit strategies to check. The flow of handling requests:
- Run all the rules that apply to the request path
- Rules answer whether to allow or deny the request.
API: This layer is an interface for other programs to call the rate limiter.
For example, this part can be exposed to the API gateway. We will not implement the API, but we will implement the logic to rate limit requests. Separating the API and rate limit service is helpful as we can expose different interfaces to integrate with other tools, for example:
- Importing the rate limiter directly into the app
- Making it available as a Kong plugin
The rule structure is part of the application interface. Users can define them to rate limit the services, and just like an API, we don’t change them much.
On the other hand, the LimitStrategy and Storage can be swapped and replaced with different implementations. So a rule can stay the same while the limiter enforcing the rule can be changed to relax the rule or make it more strict.
Implementation #
Defining Interfaces #
Based on the above rule structure we can use the following structure:
from dataclasses import dataclass
from enum import Enum
from typing import List, Optional
class Unit(str, Enum):
SECOND = "second"
MINUTE = "minute"
HOUR = "hour"
def to_seconds(self) -> int:
if self == Unit.SECOND:
return 1
elif self == Unit.MINUTE:
return 60
elif self == Unit.HOUR:
return 3600
else:
raise ValueError(f"Unknown unit: {self}")
@dataclass
class Descriptor:
key: str
unit: Unit
requests_per_unit: int
value: Optional[str] = None
@dataclass
class Rule:
path: str
descriptors: List[Descriptor]
def match(self, path: str) -> bool:
return self.path == path
dataclass is used here for easier initialization.
Now let’s define the storage interface
from abc import ABC, abstractmethod
from enum import Enum
class StorageEngines(str, Enum):
REDIS = "redis"
MEMORY = "memory"
class AbstractStorage(ABC):
@abstractmethod
def get(self, key):
raise NotImplementedError
@abstractmethod
def set(self, key, value, ttl_seconds: int):
raise NotImplementedError
get and set are the required methods for implementing the above algorithms.
other operations such as decr
are also available which can increase the performance of our code.
Limit strategies only depend on the storage & rule components. It should also have a request type for itself which can be used by other components calling it to pass in a request with a generic form. So it does not depend on a specific type of request, but only it’s data and path.
The only public function is do_limit
which takes in a request and determines if it’s limited or not.
class LimitStrategies(str, Enum):
TOKEN_BUCKET = "token_bucket"
@dataclass
class Request:
path: str
data: dict
class AbstractStrategy(abc.ABC, metaclass=abc.ABCMeta):
def __init__(
self,
storage_backend: AbstractStorage,
rule_descriptor: Descriptor,
) -> None:
self.storage_backend = storage_backend
self.rule_descriptor = rule_descriptor
@abc.abstractmethod
def do_limit(
self,
request: Request,
):
raise NotImplementedError
Token Bucket #
Now that the interfaces are clear we can start implementing the algorithm.
From the rule structure,
we can use the unit to to refresh tokens in the bucket.
and the request_per_unit to determine bucket capacity.
class TokenBucket(AbstractStrategy):
def __init__(
self,
storage_backend: AbstractStorage,
rule_descriptor: Descriptor,
):
su
Test Rate Limiter Service #
For rate limiter service we need to create two fixtures, config and local storage:
@pytest.fixture
def local_storage():
yield memory.Memory()
@pytest.fixture
def config():
return Config(
limit_strategy=LimitStrategies.TOKEN_BUCKET,
)
Now what can be tested in the service? With the limit strategy we were testing if the rule descriptor is applied correctly.
Here we should check if the rule is applied correctly, this means we can still test the rule descriptor part, but it’s not necessary since if a rule descriptor is not applied correctly then the limit strategy test must throw an error(otherwise we end up with an untested strategy which is a nightmare).
def test_rate_limit_service_applies_the_rule(local_storage: memory.Memory, config: Config):
rule_descriptor = Descriptor(
key="user_id",
requests_per_unit=1,
unit=Unit.SECOND,
)
rule = Rule(path="/limited-path", descriptors=[rule_descriptor])
rate_limit_service = RateLimitService(
config=config, storage_engine=local_storage, rules=[rule]
)
request = Request(path="/limited-path", data={"user_id": "1"})
assert rate_limit_service.do_limit(request) is False
assert rate_limit_service.do_limit(request) is True
time_now = datetime.datetime.now() + datetime.timedelta(seconds=3)
with freezegun.freeze_time(time_now):
assert rate_limit_service.do_limit(request) is False
Conclusion #
So far we have a working rate limiter with one implemented rule. I think this would be enough for one read, In the next post we will add more rate limiting algorithms and see how the current structure of the program can be extended.
You can find the complete source code on my Github.