AWS CDK is a tool that lets you define your cloud resources in a languages such as python. And like any other project as the codebase grows, it needs to be split into components.
CDK projects can be split into multiple stacks. Stack is a single deployable unit in CDK. when you deploy it all the resources inside it will get deployed.
Knowing a few points in the beginning can help to create a good project structure, and avoiding common pitfalls like dependency issues.
The questions to ask when considering splitting a stack:
- Which components should be extracted?
- Should this new code be a stack or a construct?
- which components belong to this stack?
- What cross-stack dependencies are created?
I’m sharing the lessons I learned writing and refactoring multiple cdk projects.
Splitting stacks
When components can be deployed separately, it’s good to split the stacks. Smaller stacks are deployed faster and it’s easier to maintain them.
You can extract some parts of a stack into another stack and add it as a dependency.
Keep in mind that when StackA depends on StackB then:
- To Deploy
StackAtheStackBmust be deployed. - When stacks are deployed
StackBcannot be updated without updatingStackAfirst.
This two way relation can cause problems which we’ll talk about it later.
How to Decide the Number of Stacks?
A simple rule for separation is based on:
- Application domain
- Resources life cycle
Multiple stacks for apps in different domains is a separation based on domain. Separating based on life cycle can be done for rarely deployed resources like databases.
You can find a good reference on these examples and stacks in open-cdk guide.
Creating constructs
CDK has another solution for having smaller stacks which is creating a re-suable component called construct. To decide whether a code should be a stack or a construct we can check:
- Can be used in other places: a S3 Bucket with specific options.
- A second stack would be always deployed deleted with current stack(highly coupled).
Creating constructs is also easier; because you are not introducing any dependencies between stacks. If you delete an stack all constructs inside it are removed.
Separated Stacks and Dependencies
Imagine we have an API with lambda and API gateway, and a route53 hosted zone. This infrastructure has two properties:
- Lambda can frequently be changed, but the API endpoint is same.
- deploying a resource like a hosted zone takes a lot of time. So it’s better to deploy it separately, once.
- A hosted zone record must point to API endpoint.
By splitting this stack into two:
- API stack
- Hosted zone stack
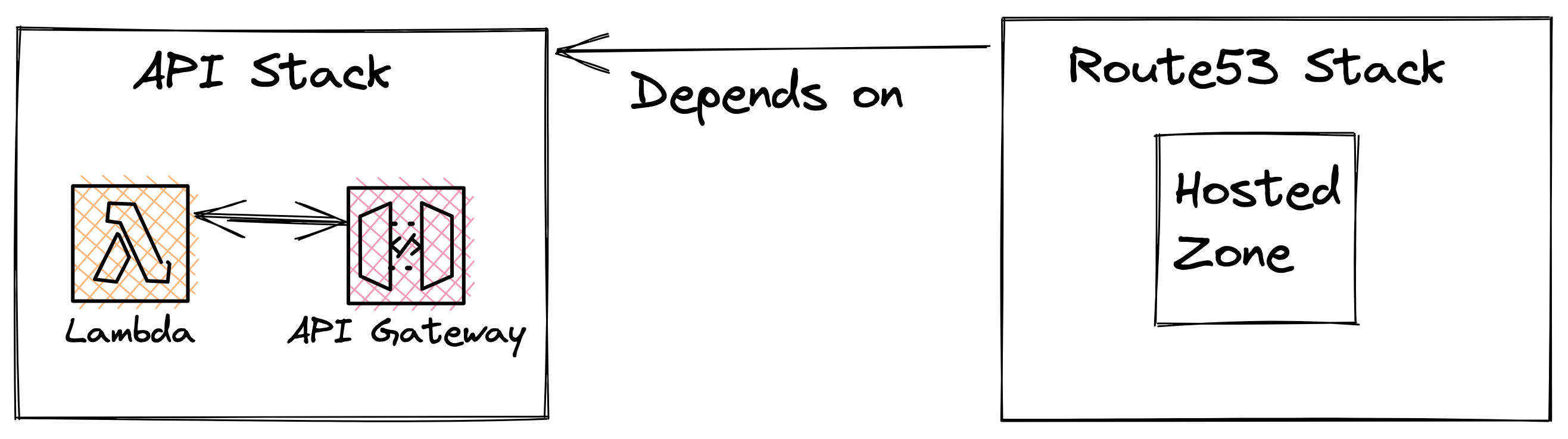
Dependency problem and Solution
What dependencies did we create? If our API endpoint changes then the Hosted zone needs to be updated to point to the new endpoint. This dependencies between stack, can cause problems if not considered carefully. If you now try to update the API endpoint(which is part of API stack) when all the stacks are deployed you will get the following error:
Export ApiStack:ExportsOutputFnGetAtt-******
cannot be deletedas it is in use by HostedZoneStack
The issue is that the Hosted Zone stack is using the referenced endpoint from ApiStack and without deleting the hosted zone you cannot delete the reference.
You have two solutions to either destroy them both or do a 2 phase deployment. Although the 2 phase deployment always works it’s manual work. It’s fine for a database migration but this should not be something to do every week.
Solution to prevent the issue: Document not changing parts in your CDK app. Our assumption is that our API endpoint is not going to change frequently, otherwise we are just deploying stacks together all the time.
Another solution is to use parameter store to reference these dependencies. In this method you can change anything since CDK does not know about your dependencies. The downside of this method is that you have to manage dependencies now, actually you are now the compiler :D.
I would not recommend this method Because you are loosing the type checks,
like any in a typed language.
It’s a solution where you want to share resources between multiple CDK apps where you can’t pass the objects. For example if you are referencing DB name in applications as env vars, it’s better to save the DB name in parameter store and retrieve in runtime. Because that resource can be deployed multiple times but your app does not need to be redeployed.
Now Let me give you a Bad splitting example:
Imagine we have a EC2 with an application load balancer. The EC2 id must be set in load balancer to route the traffic.
If we try to separate these into load balancer and app stacks, when ever we want to redeploy the EC2 the other stack must be destroyed and redeployed.
Remove Security Group dependencies
A common dependency between stacks is the security group rules. For example we have a database with and we want our EC2 to access it. One solution could be:
// DB Stack
dbInstance = ...
// App Stack
dbInstance.connections.allowFrom(ec2Instance, ec2.Port.tcp(5432));
But in this code DB stacks depends on the EC2 instance which can change. Is there a way to make our database stack completely independent?
Surprisingly you can use the dependency inversion principle:
Low level policies should depend upon high level policies.
How can we make the application dependent on database in this case? We can just flip the dependency.
// DB stack
dbInstance = ...
// App stack
Ec2 = new ec2.Instance(...)
Ec2.connections.allowTo(Db, ...)
With this method your database is not aware of what resources are connected to it. You made it a high level policy and other services are now aware of how to connect.
Remove unnecessary dependencies
Removing redundant dependencies reduces the overhead of managing them between stacks. The security group was an example of how to do this. Important lesson here is to understand how each line of CDK is connecting your resources together.
Conclusion
Knowing how to split stacks is an art of managing dependencies. When I first started to do it before knowing these topics, I ran into issues I did not except and it helped me see the problem from a different aspect. It’s not only about separating code but it’s about which resources should be grouped.
I hope knowing this will help you avoiding this common pitfall.